Pedestrian Detection
Pedestrian Detection with Semantic Tasks1
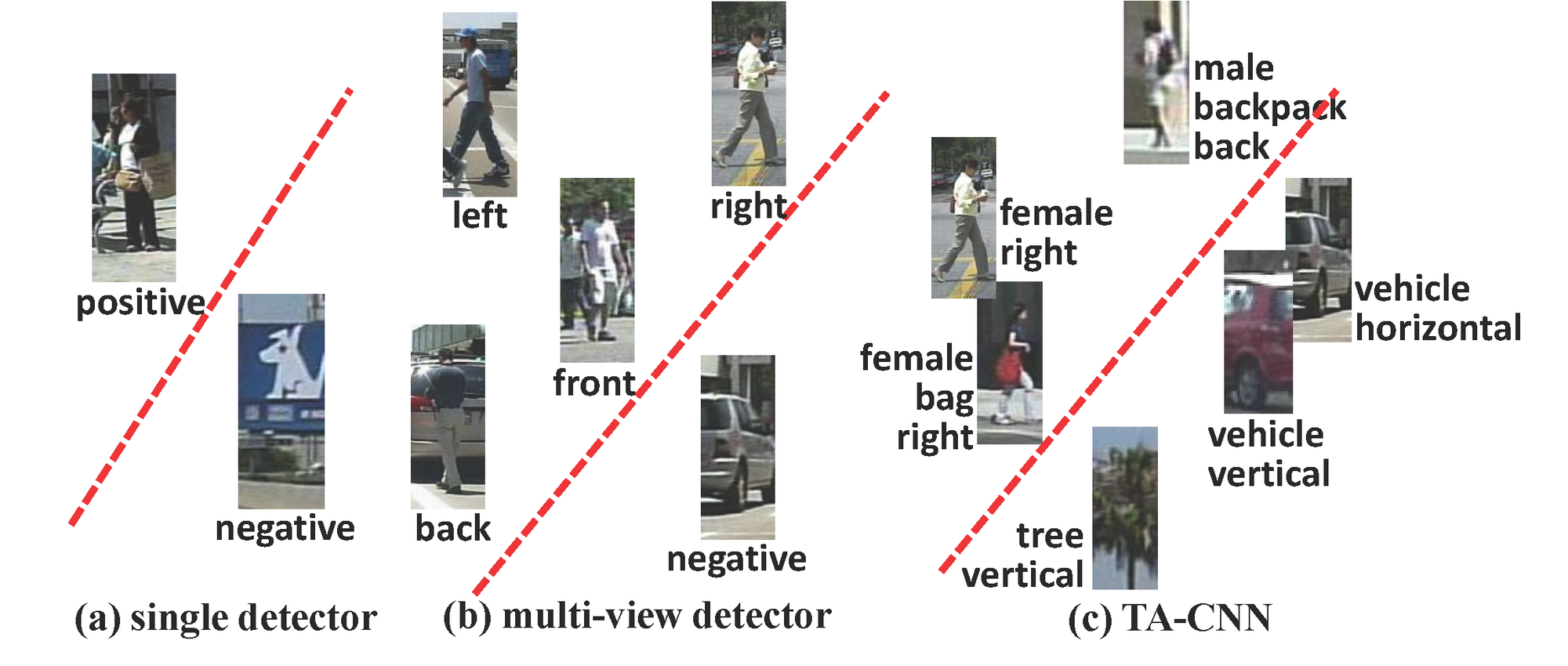
Deep learning methods have achieved great successes in pedestrian detection, owing to its ability to learn discriminative features from raw pixels. However, they treat pedestrian detection as a single binary classification task, which may confuse positive with hard negative samples. To address this ambiguity, this work jointly optimize pedestrian detection with semantic tasks, including pedestrian attributes (e.g. carrying backpack) and scene attributes (e.g. vehicle, tree, and horizontal). Rather than expensively annotating scene attributes, we transfer attributes information from existing scene segmentation datasets to the pedestrian dataset, by proposing a novel deep model to learn high-level features from multiple tasks and multiple data sources. Since distinct tasks have distinct convergence rates and data from different datasets have different distributions, a multi-task deep model is carefully designed to coordinate tasks and reduce discrepancies among datasets. Extensive evaluations show that the proposed approach outperforms the state-of-the-art on the challenging Caltech and ETH datasets where it reduces the miss rates of previous deep models by 17 and 5.5 percent, respectively.
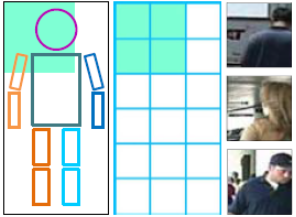
We manually label the pedestrian attributes of Caltech Pedestrian dataset (every 30th frame which follows the standard training and testing protocol).
Contribution Highlights
- Discriminative representation for pedestrian detection is learned by jointly optimizing with semantic attributes, including pedestrian attributes and scene attributes. The scene attributes can be transferred from existing scene datasets without annotating manually.
- Multiple tasks from multiple sources are trained using a single task-assistant CNN (TA-CNN), which is carefully designed to bridge the gaps between different datasets
- We systematically investigate the effectiveness of attributes in pedestrian detection.
Download
- Pedestrian attribute labels can be download here.
- Detection results for Caltech and ETH datasets can be download here.
Pedestrian Detection with Switchable RBM2
We propose a Switchable Deep Network (SDN) for pedestrian detection. The SDN automatically learns hierarchical features, salience maps, and mixture representations of different body parts. Pedestrian detection faces the challenges of background clutter and large variations of pedestrian appearance due to pose and viewpoint changes and other factors. One of our key contributions is to propose a Switchable Restricted Boltzmann Machine (SRBM) to explicitly model the complex mixture of visual variations at multiple levels. At the feature levels, it automatically estimates saliency maps for each test sample in order to separate background clutters from discriminative regions for pedestrian detection. At the part and body levels, it is able to infer the most appropriate template for the mixture models of each part and the whole body. We have devised a new generative algorithm to effectively pretrain the SDN and then fine-tune it with back-propagation. Our approach is evaluated on the Caltech and ETH datasets and achieves the state-of-the-art detection performance.

Pedestrian Detection with Strong Part Models3
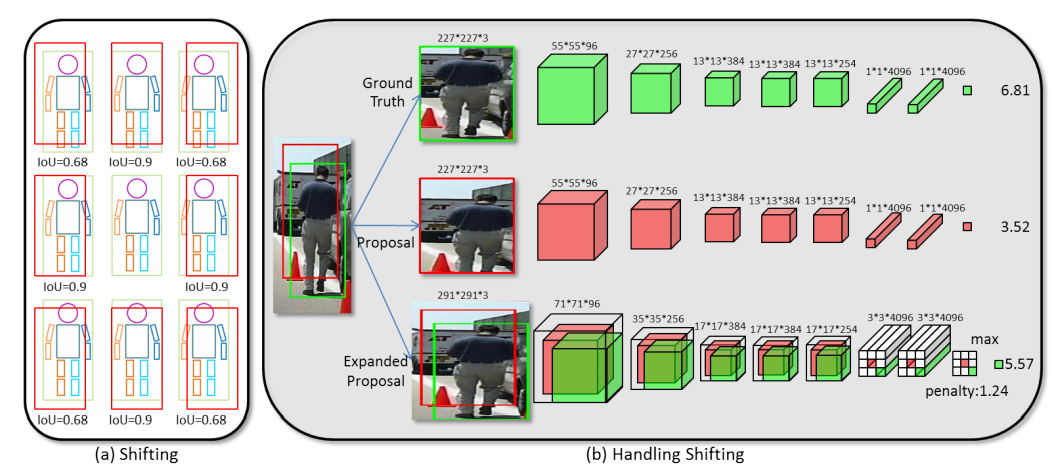
Recent advances in pedestrian detection are attained by transferring the learned features of Convolutional Neural Network (ConvNet) to pedestrians. This ConvNet is typically pre-trained with massive general object categories (e.g. ImageNet). Although these features are able to handle variations such as poses, viewpoints, and lightings, they may fail when pedestrian images with complex occlusions are present. Occlusion handling is one of the most important problem in pedestrian detection. Unlike previous deep models that directly learned a single detector for pedestrian detection, we propose DeepParts, which consists of extensive part detectors. DeepParts has several appealing properties. First, DeepParts can be trained on weakly labeled data, i.e. only pedestrian bounding boxes without part annotations are provided. Second, DeepParts is able to handle low IoU positive proposals that shift away from ground truth. Third, each part detector in DeepParts is a strong detector that can detect pedestrian by observing only a part of a proposal. Extensive experiments in Caltech dataset demonstrate the effectiveness of DeepParts, which yields a new state-of-the-art miss rate of 11.89%, outperforming the second best method by 10%.
-
Y. Tian, P. Luo, X. Wang, X. Tang, Pedestrian Detection aided by Deep Learning Semantic Tasks, CVPR 2015 ↩︎
-
P. Luo, Y. Tian, X. Wang, X. Tang , Switchable deep network for pedestrian detection, CVPR 2014 ↩︎
-
Y. Tian, P. Luo, X. Wang, X. Tang, Deep Learning Strong Parts for Pedestrian Detection, ICCV 2015 ↩︎
Ping Luo
Associate Professor, Computer Science, The University of Hong Kong
My research interests include deep learning, computer vision, and artificial intelligence.