
Introduction
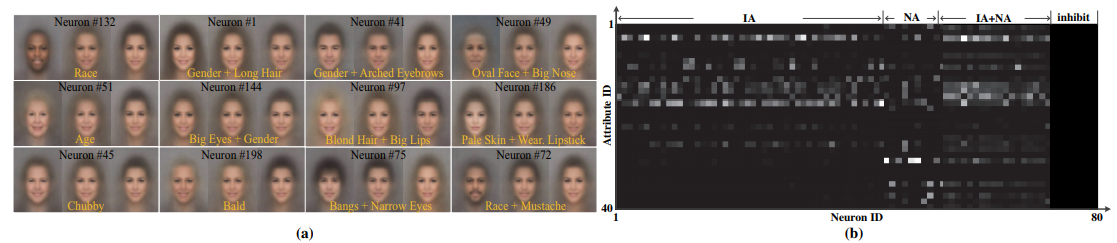
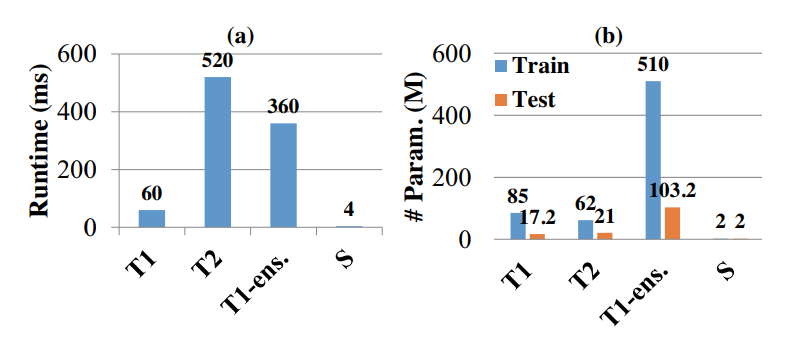
The recent advanced face recognition systems were built on large Deep Neural Networks (DNNs) or their ensembles, which have millions of parameters. However, the expensive computation of DNNs make their deployment difficult on mobile and embedded devices. This work addresses model compression for face recognition, where the learned knowledge of a large teacher network or its ensemble is utilized as supervision to train a compact student network. Unlike previous works that represent the knowledge by the soften label probabilities, which are difficult to fit, we represent the knowledge by using the neurons at the higher hidden layer, which preserve as much information as the label probabilities, but are more compact. By leveraging the essential characteristics (domain knowledge) of the learned face representation, a neuron selection method is proposed to choose neurons that are most relevant to face recognition. Using the selected neurons as supervision to mimic the single networks of DeepID2+ and DeepID3, which are the state-of-the-art face recognition systems, a compact student with simple network structure achieves better verification accuracy on LFW than its teachers, respectively. When using an ensemble of DeepID2+ as teacher, a mimicked student is able to outperform it and achieves 51.6x compression ratio and 90x speed-up in inference, making this cumbersome model applicable on portable devices.
Supplementary Material: download.
Ping Luo
Associate Professor, Computer Science, The University of Hong Kong
My research interests include deep learning, computer vision, and artificial intelligence.