CUImage Dataset
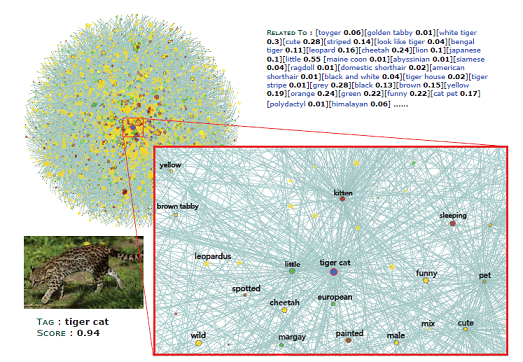
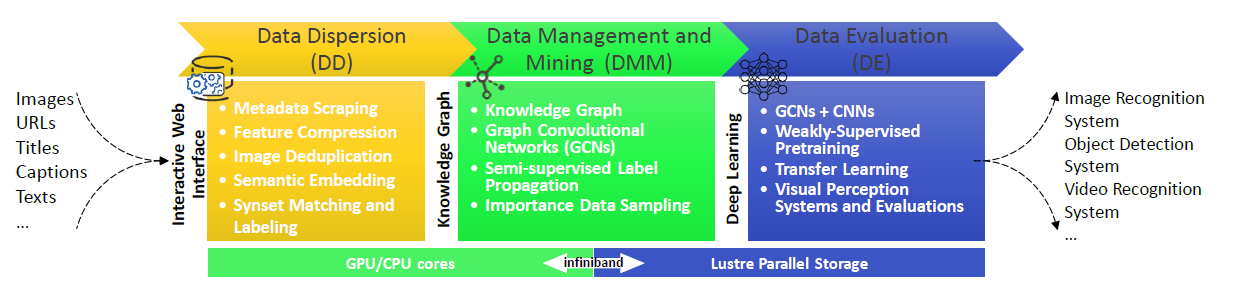
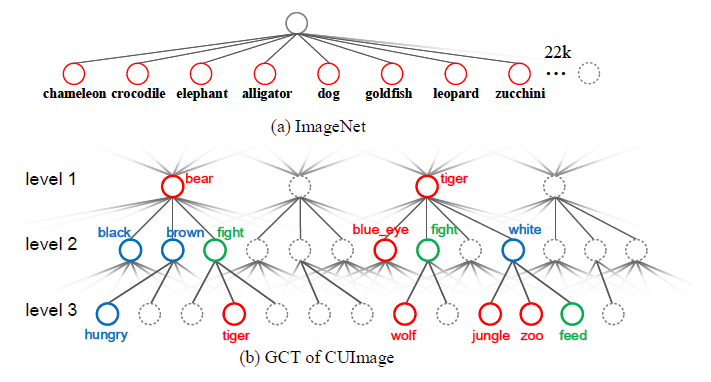
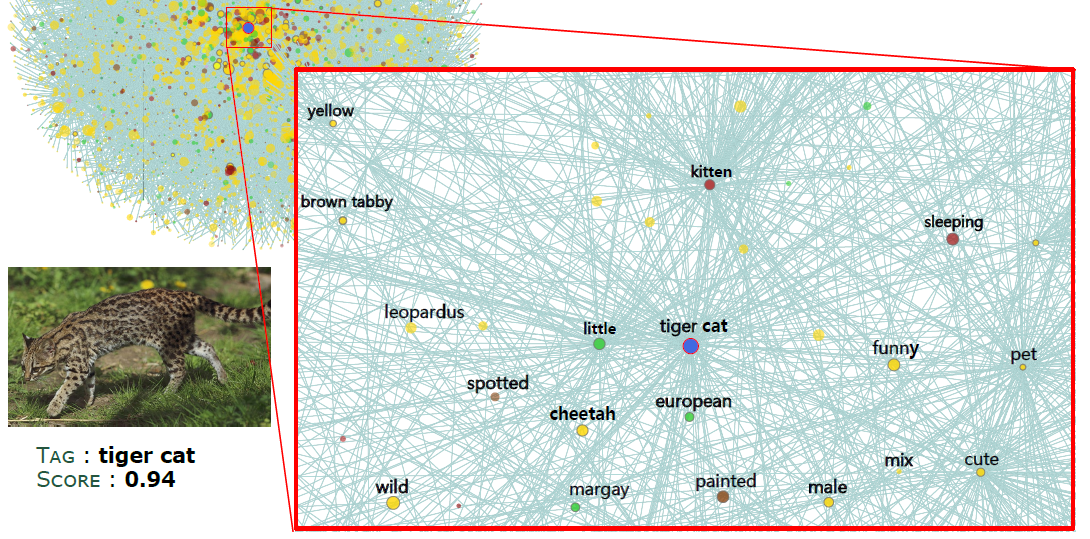
Pretraining visual features by image classification on ImageNet is an indispensable step towards many advanced perception systems in the last decade. ImageNet is the most prevalent database for supervised pretraining of image features. Unlike ImageNet assuming that the visual concepts are static and independent with each other, this work presents a neverending learning platform, termed CUImage, which learns visual representation on a knowledge graph of billions of images, whose data scale is several orders of magnitude larger than ImageNet. A novel dynamic graph convolutional network (GCN) is proposed to learn visual concepts. Once the new data are presented, the GCN is updated dynamically where new concepts can be discovered or existing concepts can be merged. This is enabled by three main components in CUImage, including Data Dispersion (DD), Data Management and Mining (DMM), and Data Evaluation (DE). These three components are built on top of a computer cluster with thousands of GPU/CPU cores and a parallel storage of petabytes. So far, CUImage has processed and managed more than 2 million visual concepts of 2 billion images. To evaluate the learned representation, we transfer the pretrained features to several challenging benchmarks such as image recognition on ImageNet and object detection in MS-COCO. We achieve state-of-the-art results, significantly surpassing the systems that used ImageNet for pretraining.
Ping Luo
Associate Professor, Computer Science, The University of Hong Kong
My research interests include deep learning, computer vision, and artificial intelligence.